RAG nodes
The RAG category contains two nodes for working with content stores (vector databases used for retrieval-augmented generation):
| Node | Description |
|---|---|
| Search Content Store | Semantic search across RAG content — returns matching chunks |
| Reindex Content Store | Trigger reindexing of content stores, DMS links, or web crawlers |
Search Content Store
Performs semantic (vector) search against your project’s content stores and returns the most relevant document chunks.
When to use
- Retrieve relevant context before an LLM call (RAG pattern)
- Find documents matching a user query
- Search knowledge bases, uploaded files, or crawled web content
Configuration
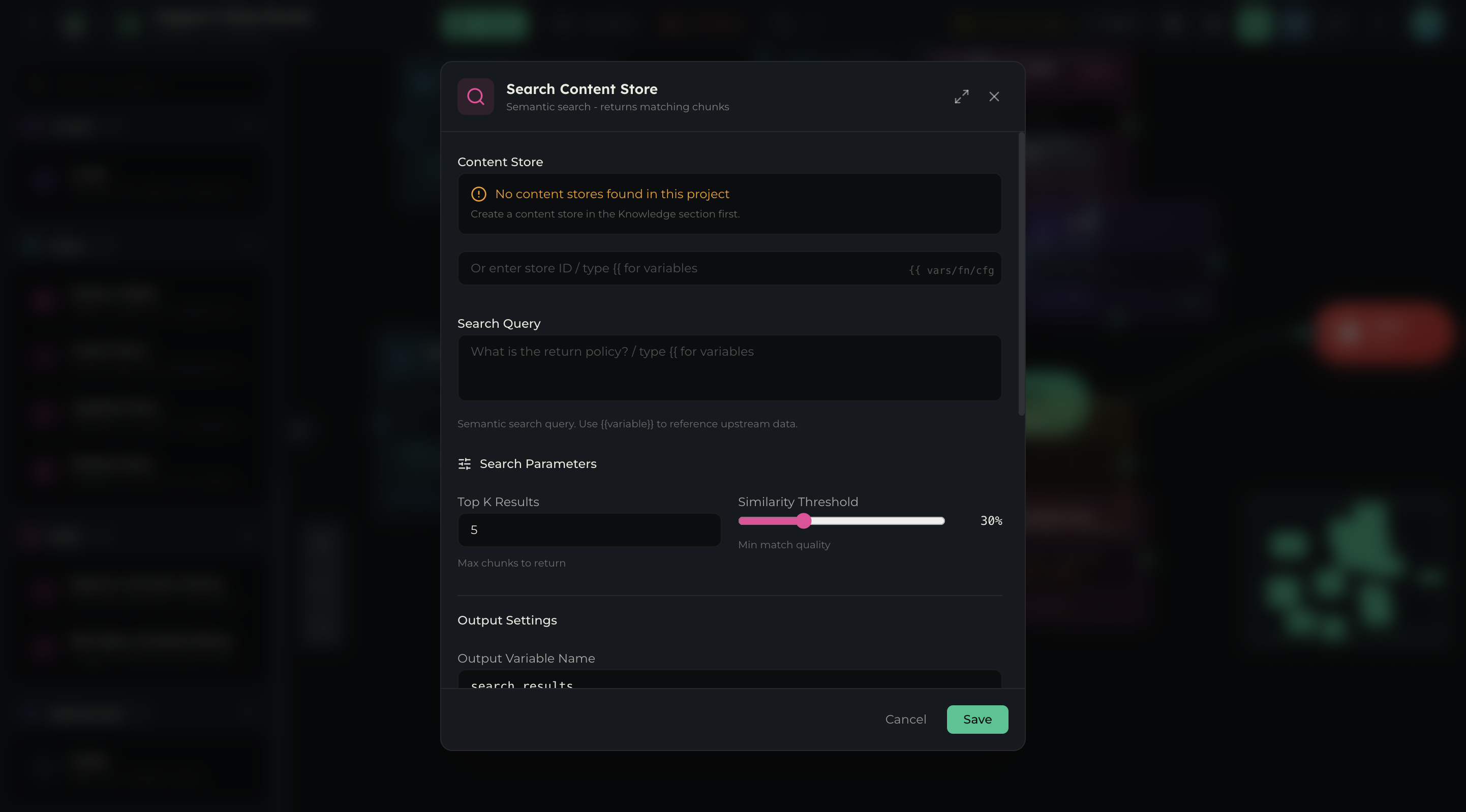
| Setting | Type | Description |
|---|---|---|
| Content Store | Dropdown | Select which content store to search |
| Search Query | Text field (supports {{variable}}) | Semantic search query — use {{variable}} to reference upstream data |
| Top K Results | Number input (default: 5) | Maximum number of chunks to return |
| Similarity Threshold | Slider (default: 0.3 / 30%) | Minimum match quality to include a result |
| Output Variable Name | Text field (default: search_results) | Access as {{output.<name>}} — returns array of chunks |
Include in Results (all checked by default):
| Option | Description |
|---|---|
| Chunk content text | The matched text content |
| Source metadata | Document metadata (tags, dates) |
| Similarity scores | Match quality score per chunk |
| Source info | Filename, URL, and origin details |
Output schema
{
"chunk_id": "string",
"content": "string",
"score": 0.85,
"source": { "filename": "...", "url": "..." },
"metadata": { ... }
}Edge significance
Linear flow: single input → single output edge.
Reindex Content Store
Triggers a reindexing operation on a content store. This re-processes source documents and updates the vector embeddings.
When to use
- After uploading new documents to a DMS-linked content store
- After a web crawler completes a new crawl
- On a scheduled basis to keep content fresh
Configuration
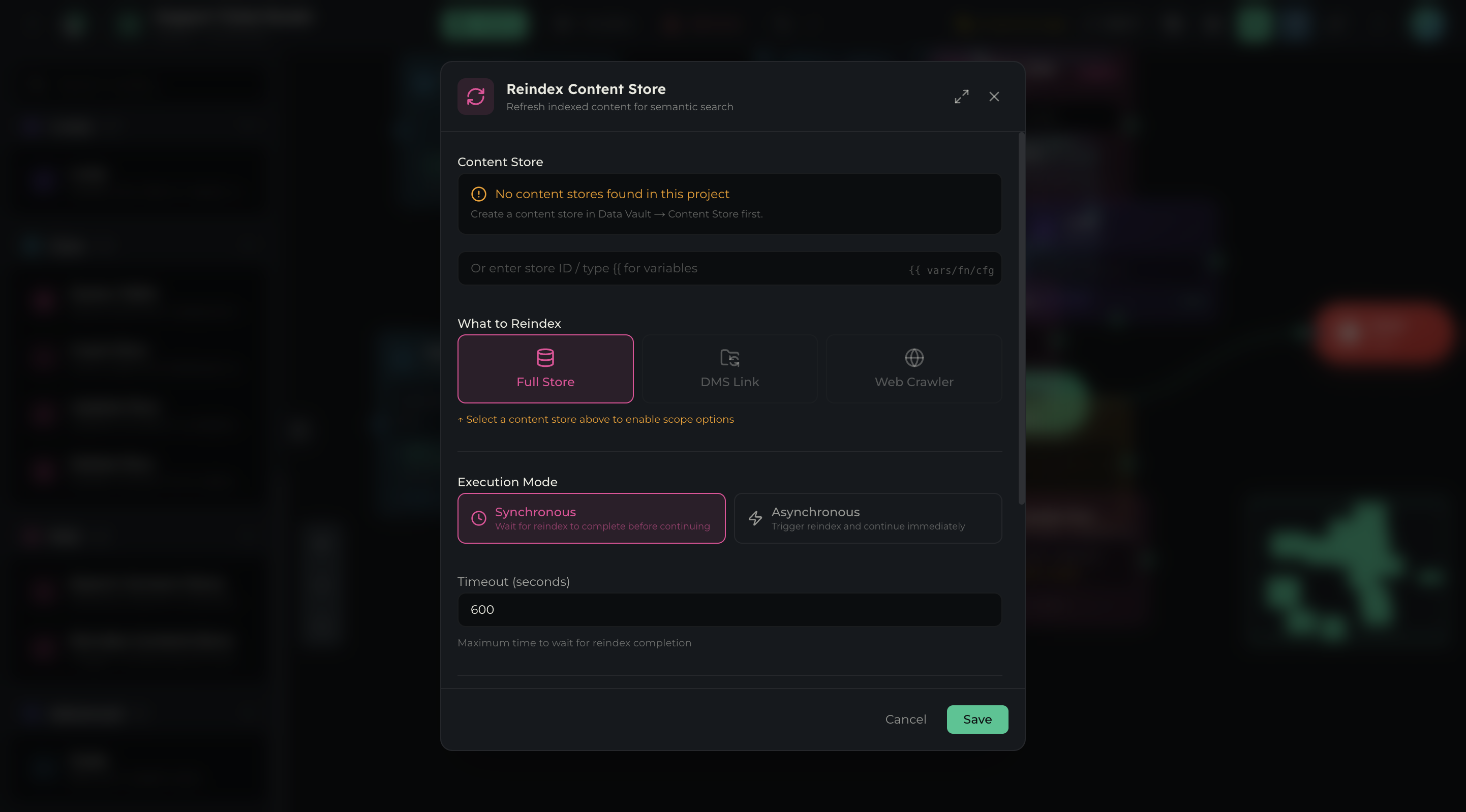
| Setting | Type | Description |
|---|---|---|
| Content Store | Dropdown or text (supports {{variable}}) | Select store or enter store ID dynamically |
| What to Reindex | Toggle buttons (3 options) | Scope of reindexing operation |
| Execution Mode | Radio cards (2 options) | Sync or Async execution |
| Timeout (seconds) | Number input (default: 600) | Max time to wait for reindex completion |
| Output Variable Name | Text field (default: reindex_result) | Variable for the operation status |
| Return job ID | Checkbox (default: checked) | Include job tracking ID |
| Return reindex statistics | Checkbox (default: checked) | Include processing stats |
What to Reindex options:
| Scope | Description |
|---|---|
| Full Store | Reprocess all documents in the store |
| DMS Link | Reindex documents from a linked DMS source |
| Web Crawler | Reindex content from a web crawler (requires store selection first) |
Execution Mode options:
| Mode | Description |
|---|---|
| Synchronous | Wait for reindex to complete before continuing |
| Asynchronous | Trigger reindex and continue immediately |
Output
Returns the reindex operation status (started, completed, or error details).
Edge significance
Linear flow: single input → single output edge.
Use Sync mode when subsequent nodes depend on updated content. Use Async mode for background reindexing when the agent doesn’t need to wait.