Code node
The Code node executes custom code within your workflow. It appears in the Advanced palette category with the description: “Execute custom code.” The node runs in a sandboxed environment with access to workflow variables and platform SDK helpers.
When to use
- Transform data between nodes (reshape, filter, calculate)
- Implement custom logic not covered by other nodes
- Call platform SDK methods (database queries, LLM calls, DMS operations)
- Parse or validate complex data structures
Configuration
Click the Code node to open its full-screen editor.
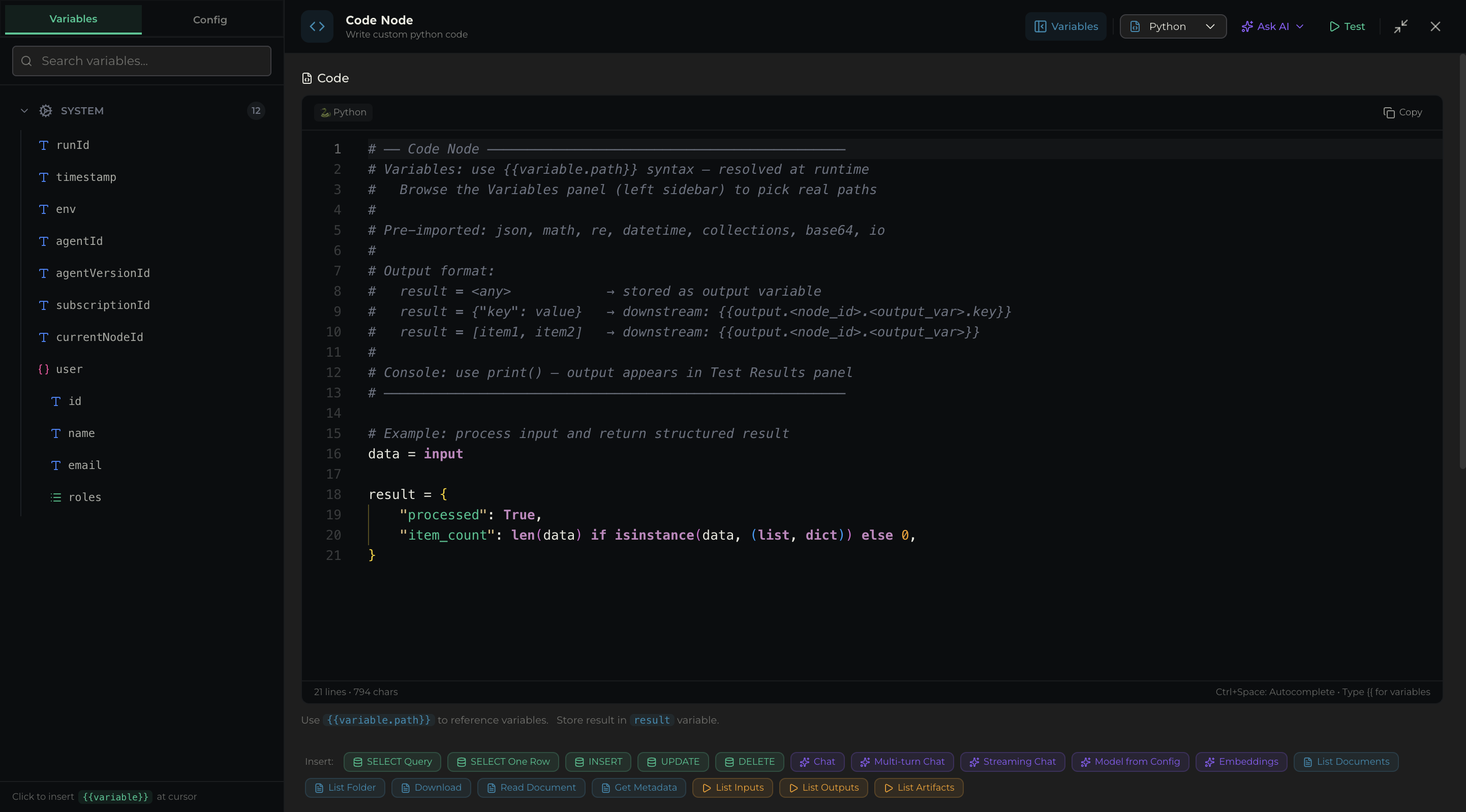
Editor toolbar
| Control | Type | Description |
|---|---|---|
| Language | Combobox (Python / JavaScript) | Code language for this node |
| Variables | Button | Opens the variable browser to insert {{variable.path}} references |
| Ask AI | Button | AI-assisted code generation |
| Test | Button | Execute the code against test data |
| Exit fullscreen | Button | Return to canvas view |
Code editor
Full-featured code editor with:
- Line numbers and syntax highlighting
{{variable.path}}interpolation (resolved at runtime)- Autocomplete (
Ctrl+Space) - Copy button
Pre-imported modules
Python: json, math, re, datetime, collections, base64, io
SDK helpers (both languages): db, llm, dms
Quick Insert snippets
Pre-built code templates accessible via buttons below the editor:
| Category | Snippets |
|---|---|
| Database | SELECT Query, SELECT One Row, INSERT, UPDATE, DELETE |
| LLM | Chat, Multi-turn Chat, Streaming Chat, Model from Config, Embeddings |
| DMS | List Documents, List Folder, Download, Read Document, Get Metadata |
| Workflow | List Inputs, List Outputs, List Artifacts |
Output settings
| Setting | Type | Description |
|---|---|---|
| Output Variable Name | Text field (default: result) | Name used in {{output.node_id.this_name}} to access the result |
Output format
Assign your result to the result variable:
result = {"status": "success", "data": processed_data, "count": 42}Downstream nodes access it as:
{{output.<node_id>.result}}→ full result object{{output.<node_id>.result.status}}→"success"{{output.<node_id>.result.count}}→42
Use print() for debugging — output appears in the Test Results panel.
Available system variables
The Variables panel (left sidebar) exposes system context:
| Variable | Type | Description |
|---|---|---|
runId | string | Current execution run ID |
timestamp | string | Execution start time |
env | string | Environment (preview/production) |
agentId | string | Current agent ID |
agentVersionId | string | Current agent version |
subscriptionId | string | Tenant ID |
currentNodeId | string | This node’s ID |
user.id | string | Current user ID |
user.name | string | User display name |
user.email | string | User email |
user.roles | array | User’s assigned roles |
Edge significance
Linear flow: single input → single output edge.
Code runs in a sandboxed environment (indicated by the “Sandboxed” badge on the canvas node). It cannot access the filesystem, network, or external processes directly — use the SDK helpers (db, llm, dms) for platform operations.
Common patterns
- Data transformation — Reshape query results before passing to an LLM prompt.
- Validation — Check data integrity and return errors if invalid.
- Aggregation — Combine results from multiple upstream nodes.
- SDK operations — Use
db.query(),llm.chat(), ordms.list()for platform calls within custom logic.